AerialMegaDepth: Learning Aerial-Ground
Reconstruction and View Synthesis
Carnegie Mellon University
(* denotes equal contribution/advising)
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2025
TL;DR: A scalable data generation framework that combines mesh-renderings with real images, enabling robust 3D reconstruction across extreme viewpoint variations.
AerialMegaDepth: A hybrid varying-altitude 3D dataset combining MegaDepth images with geospatial mesh renderings, featuring 132K images across 137 scenes with camera intrinsics, poses, and depths in a unified coordinate frame.
Overview
Learning robust 3D reconstruction across ground-to-aerial views is limited by the lack of co-registered ground-aerial training data, which is hard to collect at scale and often requires manual effort or specialized sensors. We propose a scalable framework that combines pseudo-synthetic views rendered from geospatial 3D meshes (e.g., Google Earth) with real ground-level images (e.g., MegaDepth) in a unified coordinate frame. This hybrid strategy reduces the domain gap in mesh renderings and provides diverse, viewpoint-rich supervision for multi-view tasks.
Examples of our generated cross-view geometry data, including co-registered pseudo-synthetic aerial and real ground-level images
Our Data Generation Framework
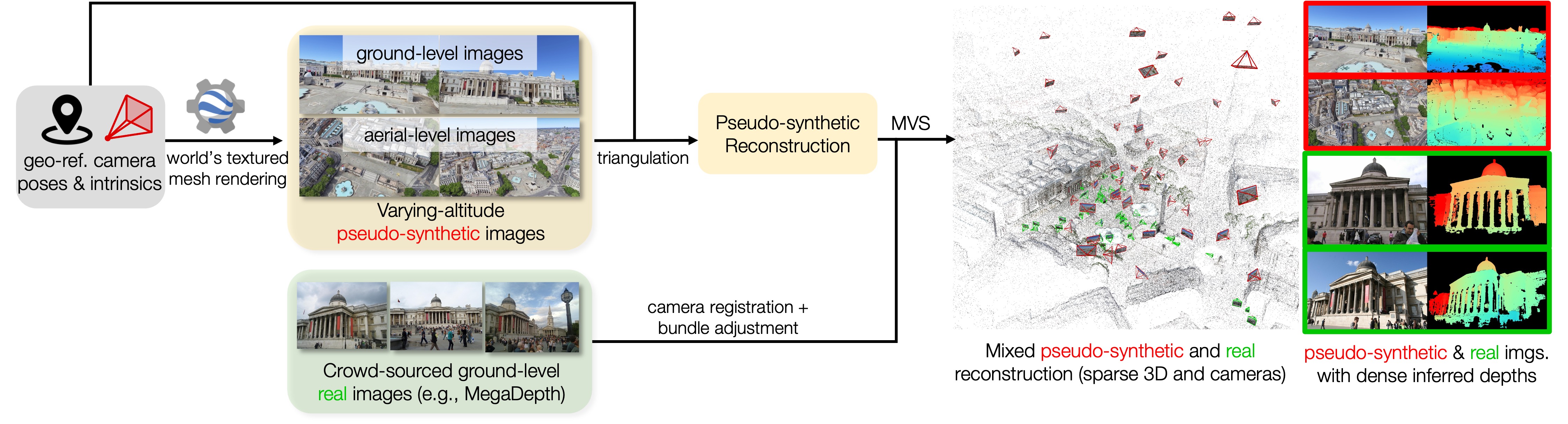

Improving aerial-ground pose and geometry estimation
By fine-tuning DUSt3R with our dataset, we observe significant improvements in handling the extreme viewpoint differences between aerial and ground-level imagery compared to the baseline DUSt3R model.
SELECT AN IMAGE PAIR
Improving aerial-ground correspondence matching
Fine-tuned MASt3R produces accurate and robust feature matching across ground-aerial pairs with extreme viewpoint changes (correspondences extracted via reciprocal-NN from MASt3R's local feature maps).
SELECT AN IMAGE PAIR
Co-registering non-overlapping ground images with aerial context
Despite the lack of overlap among ground images, incorporating an aerial image can effectively serve as a "map", significantly improving accuracy when finetuned on our cross-view training data.
SELECT AN EXAMPLE
Improving aerial-to-ground novel-view synthesis
ZeroNVS[1] finetuned on our dataset shows notable improvements in visual quality and viewpoint accuracy when synthesizing extreme aerial-to-ground viewpoint changes.

[1] ZeroNVS: Zero-Shot 360-Degree View Synthesis from a Single Image. Sargent et al., CVPR 2024.